





Elastic Cloud
Accelerate results in Elastic Cloud (Elasticsearch service)
Accelerate results that matter when you use Elastic to address your search, observability, and security challenges. Deploy in your favorite public cloud, or in multiple clouds. Extend the value of Elastic with generative AI, cloud-native features and hundreds of built-in integrations to unlock the power of data, securely and at scale.
BUY THROUGH MARKETPLACES

SEARCH. OBSERVE. PROTECT.
Benefits of Elastic Cloud
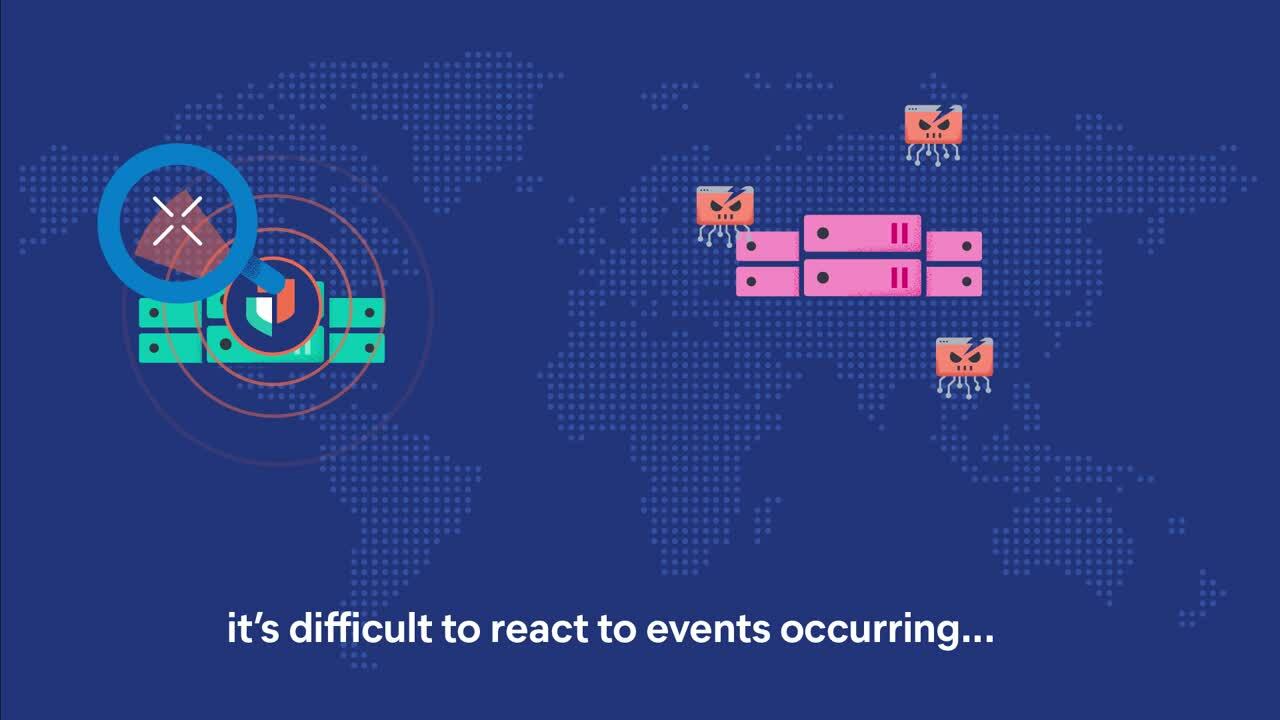
Choose a single cloud or multi-cloud to bring everything together within a single view to search and visualize your data when you need it.



Generative AI
Unlock your organization's potential with generative AI
Build tailored customer and employee experiences with large language models and generative AI using Elastic. Securely and cost-effectively link to proprietary data to provide real-time, domain-specific, accurate output, at scale.
Access. Analyze. Action.
Improve your experience with cloud‑enabled features
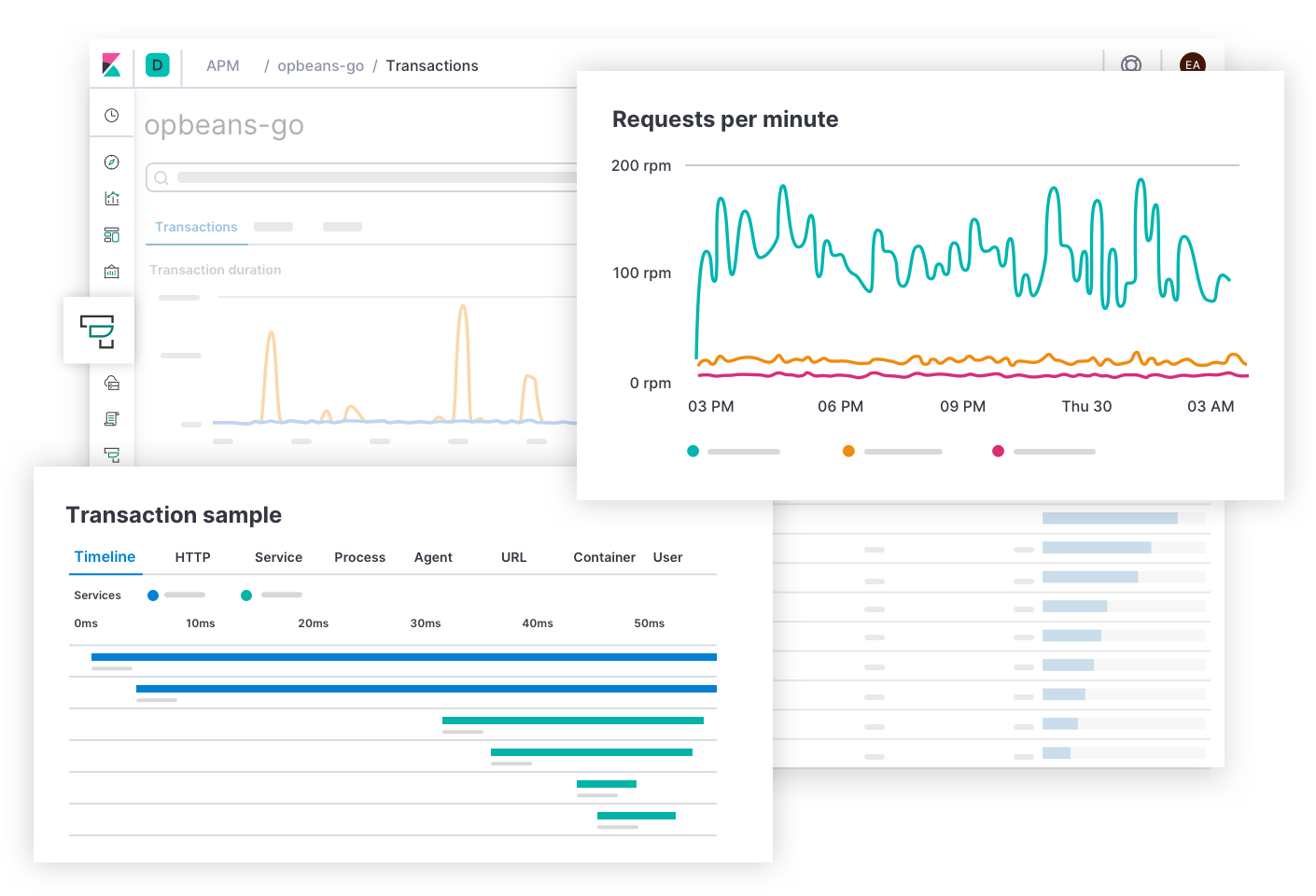
From document- and field-level security to analyzing data in real time with interactive visualizations, Elastic Cloud (the Elasticsearch service) delivers powerful features that readily extend what’s possible with the Elastic Stack.



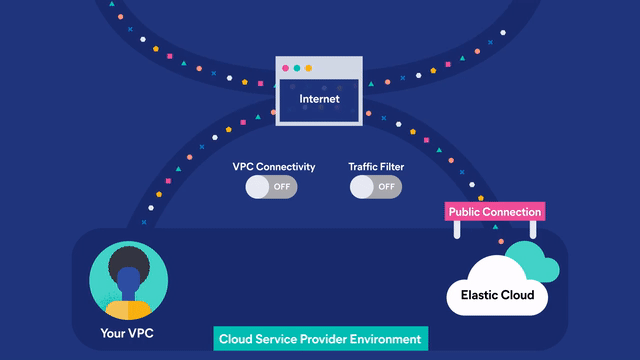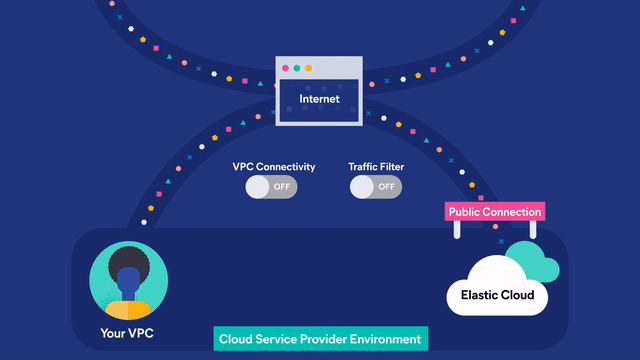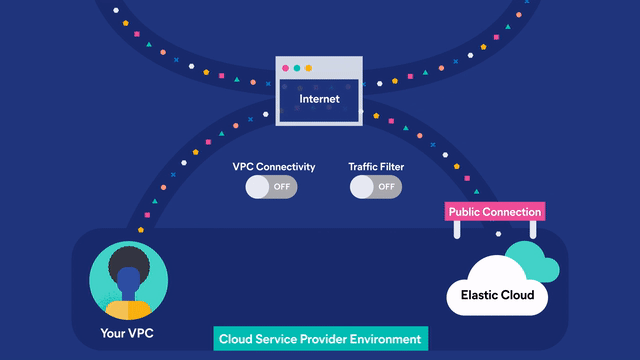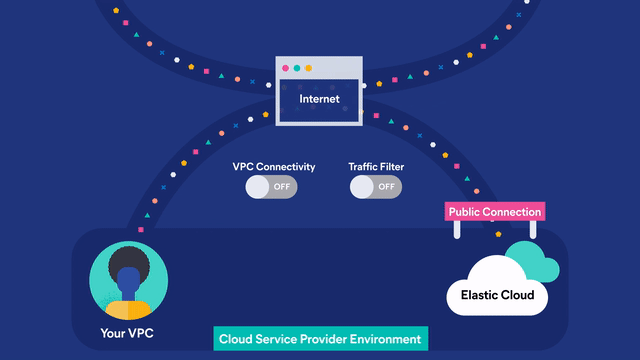
CLOUD MARKETPLACE
Experience Elastic Cloud, your way
We handle the maintenance and upkeep, so you can focus on finding the right information that will help you accelerate results that matter. Calculate the cost savings your organization can achieve by running Elastic in the cloud as a managed service. Choose any cloud — or multi-cloud or hybrid — and unify your data to derive insights with interactive visualizations and take action.



Government Ready
FedRAMP authorized
Government agencies and partners can deploy quickly and unify diverse data sets to fuel their mission-critical objectives securely in the cloud.
Trusted, used, and loved by businesses around the world






